6.2 微分信号を利用した状態の復元
6.2.1 差分近似による速度の復元
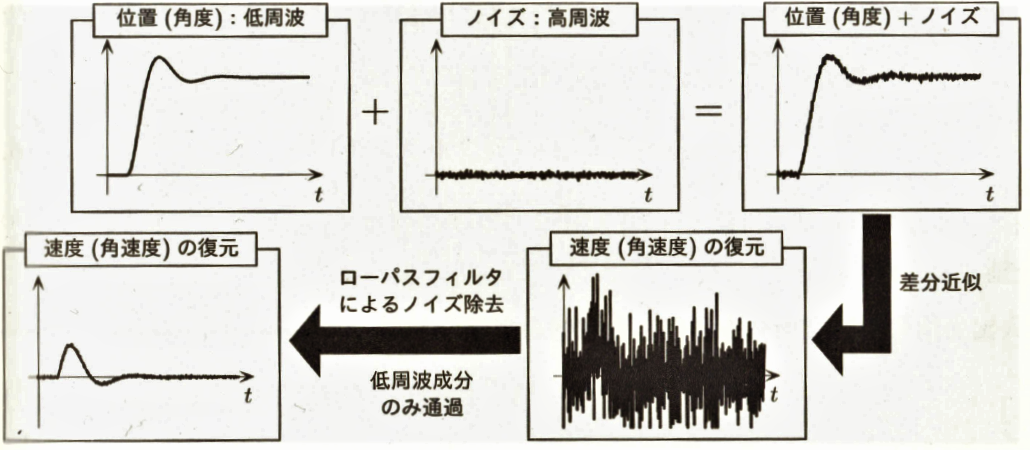
Figure 6.1 速度復元の手順
6.2.2 入出力信号の時間微分を利用した状態変数の復元
to be simplified,
where , is the observability matrix. NOTICE that is the dimension of . [ref]
Equation (6.1) is somehow similar to prediction equation [ref]page 35, pp.8, eq1.12
To distinguish, 1. the dimensions of those two are:
Equation (6.1)
:
where , and are dimensions of state variable, output and input respectively.
Equation (6.3) :
where and are prediction horizon and control horizon respectively.
2. the receding equations are:
Equation (6.1) :
Equation (6.3) :
状態変数が下より復元できる
しかし、微分の定義より、
6.3 同一次元オブザーバーによる状態推定
6.3.1 同一次元オブザーバーの構成
結論
State estimator in equation (6.6) has a fatal shortcome that it cannot deal with noise, comparing to observer in equation (6.8)
Q: 1. HOW TO WORK OUT
?
2. HOW TO SELECT OBSERVER GAIN
?
3. HOW TO DESIGN EMBEDDED CODE?
A:1. It costs time iterating to converge.
6.4 同一次元オブザーバーを利用した出力フィードバック制御
A:2.
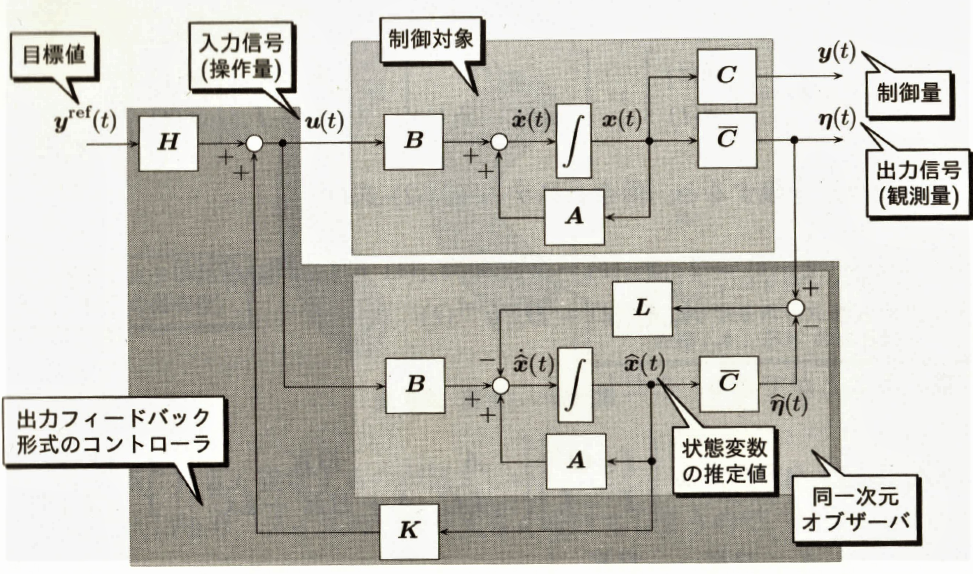
Figure 6.2 Output feedback controller using observer
where .
which can be simplified as